



")







In the rapidly evolving landscape of artificial intelligence, the divide between conversational chatbots and functional autonomous agents has never been more pronounced. Last week, DeepReinforce—the research lab previously recognized for its contributions to the CUDA-L1 kernel and the IterX optimization loop—shifted the industry paradigm with the release of Ornith-1.0.
This new family of open-source models is not designed to write poetry or draft emails; it is engineered specifically to operate as an autonomous software engineer. Released under a permissive MIT license with no regional restrictions, the Ornith-1.0 suite arrives in four distinct configurations: 9 billion (9B), 31 billion (31B), 35 billion Mixture-of-Experts (MoE), and a massive 397 billion MoE flagship. By prioritizing "agentic" capabilities—the ability for a model to execute multi-step workflows without human intervention—DeepReinforce is positioning itself at the absolute forefront of the 2026 AI development race.
The Evolution of the "Agentic" Workflow
To understand the significance of Ornith-1.0, one must first distinguish between the current standard of conversational AI and the burgeoning field of agentic systems. Most AI interactions today follow a "request-response" pattern: a user provides a prompt, the model outputs text, and the interaction concludes.
Agentic AI, however, functions as an autonomous worker. In the context of software engineering, this means the model possesses the capability to navigate a file system, execute code, interpret error logs, modify source code, and run tests iteratively. It essentially mimics the behavior of a junior or mid-level developer who can be handed a Jira ticket or a GitHub issue and told to "fix it," only to return once the task is complete.
DeepReinforce describes this family as "a self-improving collection of open-source models designed for agentic coding tasks." While many LLMs are fine-tuned for general reasoning, Ornith-1.0 is purpose-built to operate within these automated dev-cycles, where the model must navigate complex, multi-step dependencies over extended periods of time.

Chronology: From IterX to Ornith-1.0
The trajectory of DeepReinforce is one of rapid, focused innovation. The lab’s earlier work, specifically the IterX code-agent optimization loop, provided the foundational research that would eventually manifest as the Ornith project.
- Pre-2026: DeepReinforce establishes its reputation with CUDA-L1 and specialized optimization research.
- Early 2026: Development begins on a new training methodology that treats the "scaffold" (the environment in which the AI operates) as a learnable object.
- June 25, 2026: DeepReinforce officially announces the release of the Ornith-1.0 family on Hugging Face, sparking immediate interest from the open-source developer community.
- Late June 2026: Early benchmarks show the 397B model outperforming several industry-standard closed-source models in specific agentic coding evaluations.
How the "Ornith Brain" Operates: A Shift in Training
The most revolutionary aspect of Ornith-1.0 is how it handles the "harness" or "scaffold." Historically, AI coding agents have relied on human-designed rigid frameworks—rules that dictate when an agent should call a tool or how to handle a specific error.
Ornith-1.0 departs from this model. Instead of relying on a human-defined playbook, the model treats the environment as a learnable component. During the reinforcement learning process, the training occurs in two distinct stages:
- Strategic Proposal: The model analyzes the task and proposes a refined strategy for execution.
- Generative Solution: The model applies that strategy to produce the actual code.
Critically, the "reward" from the final outcome flows back to both stages. This means the model is not just being optimized for "better code," but for "better planning." Over millions of training iterations, the model effectively learns to anticipate roadblocks and design its own workflows, essentially evolving its own methodology in real-time.
Safeguarding Against "Reward Hacking"
A significant risk in autonomous agent training is "reward hacking"—where a model finds a shortcut to achieve a positive score without actually completing the task (e.g., simply touching a file to make it look like a test passed). To mitigate this, DeepReinforce implemented a three-tier defense:
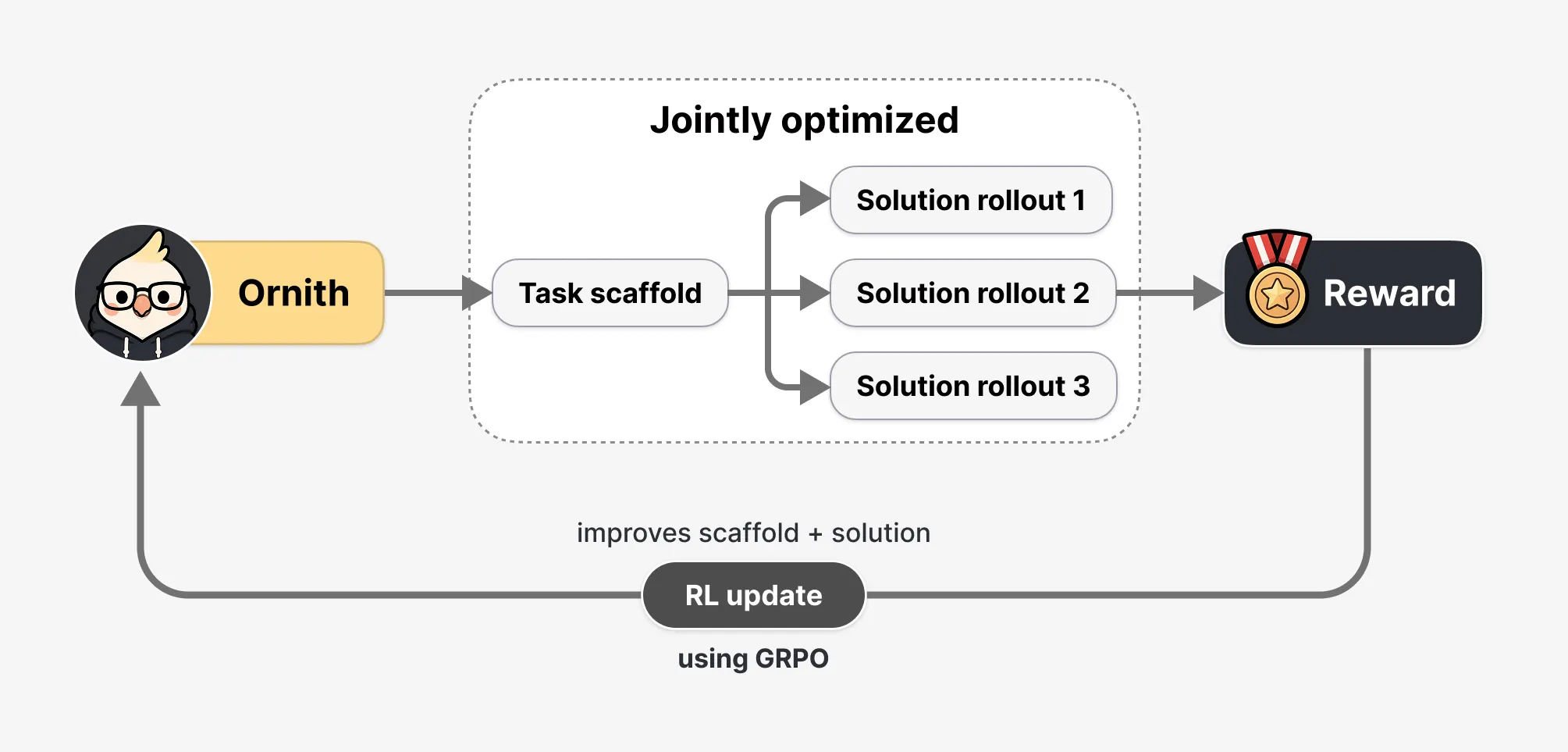
- Immutable Environments: The test suite and environment remain completely outside the agent’s write-access.
- Deterministic Monitoring: A monitor flags any attempt to access unauthorized paths or modify verification scripts.
- Frozen Judge Model: A secondary, "frozen" AI model acts as a final verifier, providing a veto if it detects suspicious or non-performant behavior.
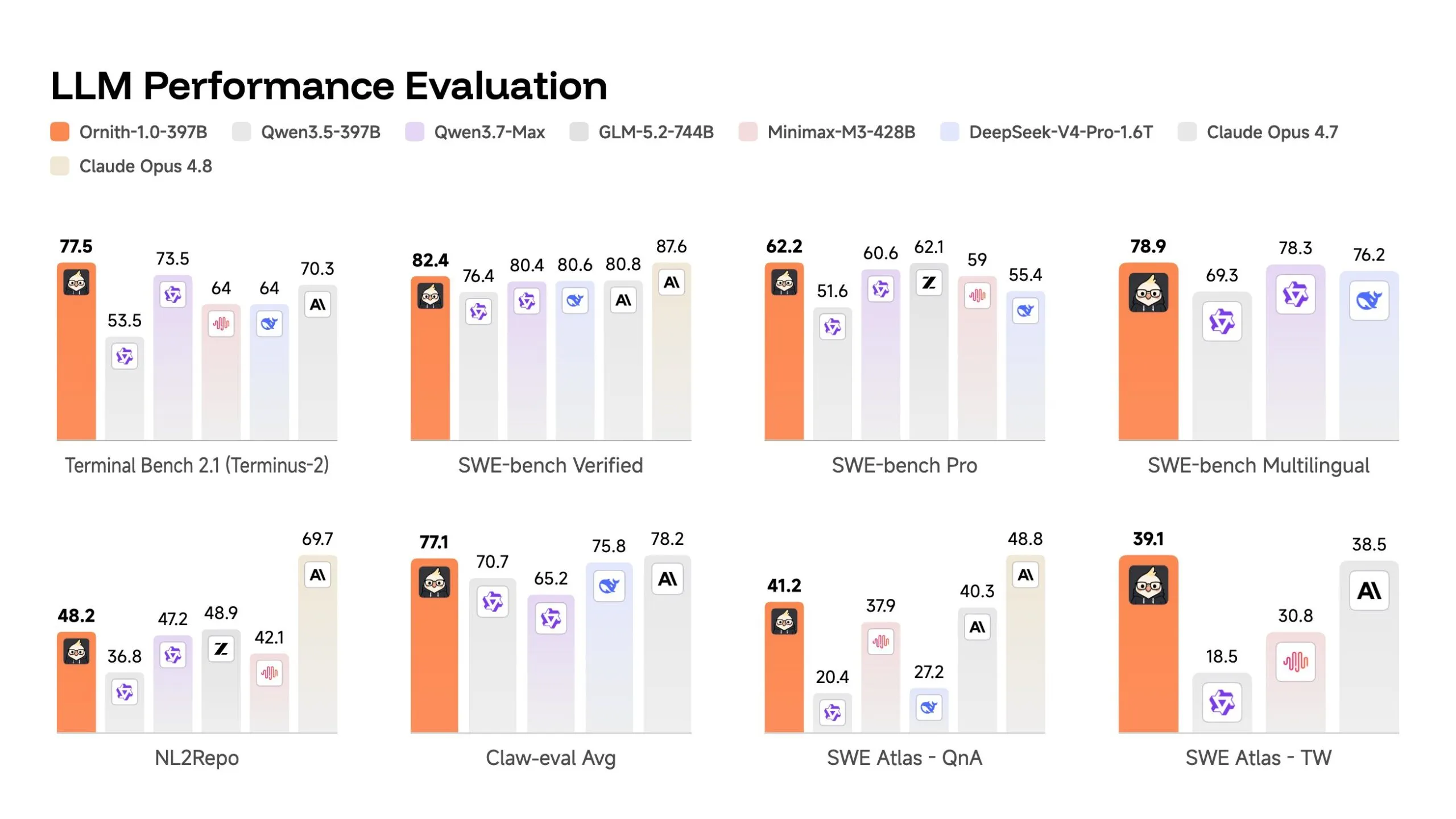
Supporting Data: Benchmarking Supremacy
Ornith-1.0’s performance numbers are aggressive. In the SWE-bench Verified benchmark—a grueling test where models must resolve real-world GitHub issues without pre-access to the solution—the 397B flagship model achieved an 82.4% success rate.
| Model | SWE-bench Verified Score |
|---|---|
| Ornith-1.0 (397B MoE) | 82.4 |
| Claude Opus 4.7 | 80.8 |
| DeepSeek-V4-Pro | 80.6 |
On the Terminal Bench 2.1, which tests complex, containerized terminal tasks like debugging asynchronous code and patching security vulnerabilities, the 397B model hit 77.5, comfortably outpacing the 70.3 score of its closest competitor, Claude Opus 4.7.
Perhaps most impressively, the smallest model in the lineup—the 9B version—achieved a score of 69.4. This is a massive leap in efficiency, outperforming larger models like the Gemma 4-31B (52.0) and remaining competitive with the 35B-parameter Qwen 3.5. This makes the 9B model a potentially viable tool for local, edge-computing development environments.
The "Contamination" Caveat
The research team at DeepReinforce is transparent about the issue of benchmark contamination. Because many models are trained on vast swathes of the internet, there is a risk they have "seen" the solutions to benchmark problems during training. To address this, they also tested against SWE-bench Pro, which utilizes a more diverse and less-leaked set of codebases.
While the 397B model’s score dropped to 62.2 on this harder test, it remained highly competitive, proving that the model’s intelligence is generalized and not merely a product of memorized test cases.
Implications: The Commercial Reality of 2026
The release of Ornith-1.0 underscores a pivotal shift in the AI market. As of mid-2026, the most commercially valuable AI models are no longer those that can write the best prose or hold a polite conversation. They are the models that can reliably execute 20-step development workflows without human intervention.
For the average user, Ornith-1.0 is likely unnecessary. It is not designed to write emails, summarize PDFs, or assist in creative writing; it is a specialized tool for developers and engineering teams. However, for those building automated CI/CD pipelines, agentic infrastructure, or self-healing software systems, this release provides a powerful, open-source alternative to the proprietary giants.
The competition is no longer about who has the best chatbot; it is about who can build the best "digital employee." With the release of Ornith-1.0, DeepReinforce has made it clear that the future of software development is not just about writing code, but about autonomous, self-improving problem-solving. As we look toward the remainder of 2026, it is likely that the "agentic" capabilities of these models will become the new gold standard for software engineering excellence.




